

Un système de recommandation est un objet informatique ayant pour but de sélectionner de l’information pertinente pour les utilisateurs d’une plate-forme (vidéos, articles, profils…). Sur YouTube par exemple, ces recommandations sont omniprésentes : en 2018, 70 % des vues de vidéos provenaient de recommandations (par opposition à des vues provenant des recherches intentionnelles). On comprend alors que cet objet est à la fois critique pour l’entreprise, qui compte sur son efficacité pour maintenir l’utilisateur sur sa plate-forme le plus longtemps possible, mais aussi critique pour l’utilisateur lui-même, pour qui la recommandation façonne l’exploration, puisque c’est principalement via ce prisme qu’il accède à l’information.
Cette double importance conduit la recherche en informatique à s’intéresser à la conception de tels recommandeurs. Il s’agit ainsi tout d’abord de prendre la perspective de la plate-forme afin d’améliorer la mise au point de la machinerie complexe qui permet à celles-ci de produire des recommandations, en général en exploitant les historiques de consommation des utilisateurs (principe du filtrage collaboratif).
La voix de la recherche, tous les jours dans vos mails, gratuitement.
L’algorithme cette boîte noire
D’un autre côté et plus récemment, la recherche s’intéresse à la perspective utilisateur de la situation. Pour analyser les algorithmes de recommandation, on les observe comme des boîtes noires. Cette notion fait référence au peu de connaissance qu’à l’utilisateur sur le fonctionnement du recommandeur qui est généralement considéré par les plates-formes comme un secret industriel. L’objectif de ces recherches est de comprendre ce qu’on peut découvrir du fonctionnement de la boîte noire sans y avoir accès, simplement en interagissant avec comme tout autre utilisateur.
L’approche consiste ainsi, en créant des profils ciblés, à observer les recommandations obtenues afin d’extraire de l’information sur la politique de la plate-forme et son désir de pousser tel ou tel catégorie ou produit, ou bien de mesurer une éventuelle censure apportée aux résultats de recherche. On notera qu’un des buts du Digital Services Act récemment discuté au parlement européen est de permettre l’audit indépendant des grandes plates-formes, c’est-à-dire de systématiser les contrôles sur le comportement de ces algorithmes.
[Près de 70 000 lecteurs font confiance à la newsletter de The Conversation pour mieux comprendre les grands enjeux du monde. Abonnez-vous aujourd’hui.]
Une illustration de ce qu’il est possible d’inférer du côté utilisateur a vu le jour dans le cadre de la campagne présidentielle de 2022 en France. Il a été tentant d’observer les recommandations « politiques », et ce pour étudier la question suivante. Puisqu’un recommandeur encode le passé des actions sur la plate-forme (ici des visualisations de vidéos), est-ce que, par simple observation des recommandations, on peut apprendre quelque chose sur l’état de l’opinion française quant aux candidats en lice pour l’élection ? Le rationnel est la boucle de rétroaction suivante : si un candidat devient populaire, alors de nombreuses personnes vont accéder à des vidéos à son sujet sur YouTube ; le recommandeur de YouTube va naturellement mettre en évidence cette popularité en proposant ces vidéos à certains de ses utilisateurs, le rendant encore plus populaire, etc.
Une expérience : les recommandations pour approximer les sondages
Pouvons-nous observer ces tendances de manière automatisée et du point de vue de l’utilisateur ? Et en particulier, que nous apprend la comparaison de ces mesures avec les sondages effectués quotidiennement durant cette période ?
Dans le cadre de cette étude, nous avons pris en compte les douze candidats présentés officiellement pour la campagne. Nous avons mis en place des scripts automatisés (bots) qui simulent des utilisateurs regardant des vidéos sur YouTube. À chaque simulation, « l’utilisateur » se rend sur la catégorie française « Actualités nationales », regarde une vidéo choisie aléatoirement, et les 4 vidéos suivantes proposées en lecture automatique par le recommandeur.
Cette action a été effectuée environ 180 fois par jour, du 17 janvier au 10 avril (jour du premier tour des élections). Nous avons extrait les transcriptions des 5 vidéos ainsi vues, et recherché les noms des candidats dans chacune. La durée d’une phrase dans laquelle un candidat est mentionné est comptée comme temps d’exposition et mise à son crédit. Nous avons agrégé le temps d’exposition total de chaque candidat au cours d’une journée et normalisé cette valeur par le temps d’exposition total de tous les candidats. Nous avons ainsi obtenu un ratio représentant le temps d’exposition partagé (TEP) de chaque candidat. Cette valeur est directement comparée aux sondages mis à disposition par le site Pollotron.
La figure présente à la fois l’évolution des sondages (en ordonnée) et les valeurs de TEP (en pointillés) pour les cinq candidats les plus en vue au cours des trois mois précédant le premier tour des élections (score normalisé en abscisse) ; les courbes sont lissées (fenêtre glissante de 7 jours). Les valeurs TEP sont moins stables que les sondages ; cependant les deux présentent généralement une correspondance étroite tout au long de la période. Cette affirmation doit être nuancée pour certains candidats, Zemmour étant systématiquement surévalué par le TEP et Le Pen inversement sous-évaluée. Il est intéressant de noter que les sondages et le TEP fournissent tous deux une bonne estimation des résultats réels des candidats lors du premier tour de l’élection (représentés par des points), présentant respectivement des erreurs moyennes de 1,11 % et 1,93 %. L’erreur moyenne de prédiction est de 3,24 % sur toute la période pour tous les candidats. L’ordre d’arrivée des candidats a été respecté par le TEP, pour ceux présents sur la figure tout au moins.
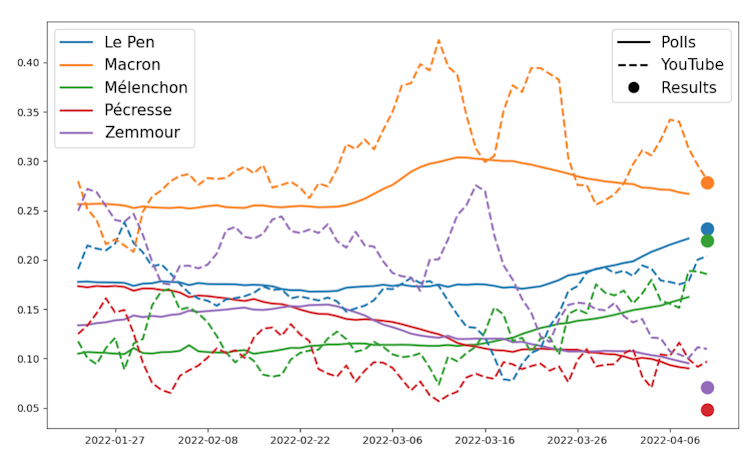
Les sondages sont effectués auprès de centaines ou de milliers d’utilisateurs tout au plus. Le recommandeur de YouTube interagit avec des millions de personnes chaque jour. Étudier de manière efficace l’observabilité et la corrélation de signaux de ce type est certainement une piste intéressante pour la recherche. Plus généralement, et avec l’introduction du Digital Services Act, il parait urgent de développer une compréhension fine de ce qui est inférable ou pas pour ces objets en boîte noire, en raison leur impact sociétal majeur et toujours grandissant.
auteurs

Chercheur en informatique, Inria

Ingénieur en machine learning, Inria

Chargé de recherche en informatique, Centre national de la recherche scientifique (CNRS)
![]()

{kind=link}